
Embeddings
the lesser known hero of AI
TYPO3 Camp RheinRuhr 2025
Frank Berger
A bit about me
- Frank Berger
- Head of Engineering at sudhaus7.de, a label of the B-Factor GmbH, member of the code711.de network
- Started as an Unix Systemadministrator who also develops in 1996
- Working with PHP since V3
- Does TYPO3 since 2005

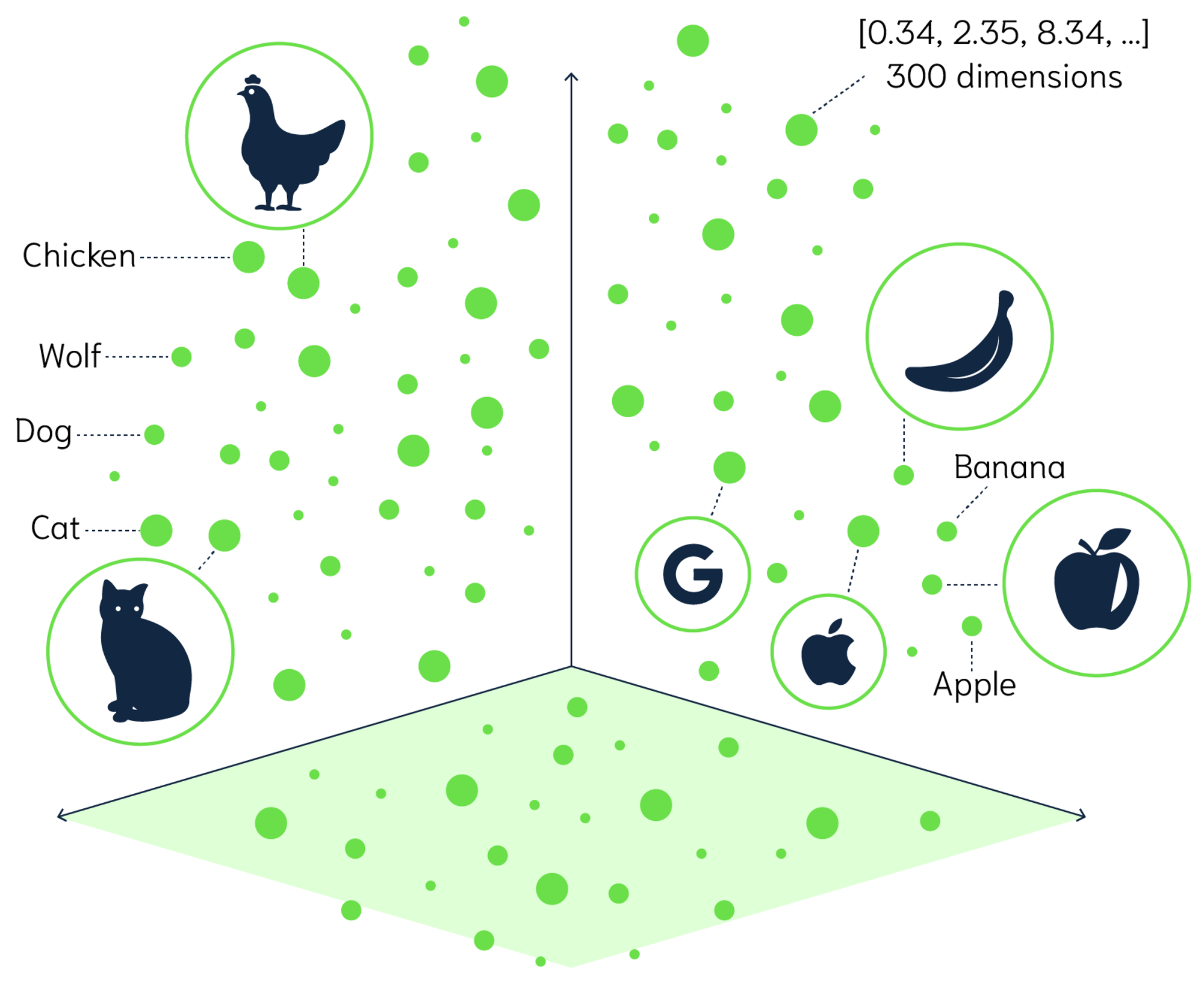
What is an Embedding?
A point in multi-dimensional space, described by a vector
Mathematically represent characteristics and meaning of a word, phrase or text
It encodes both semantic and contextual information
AI and LLMs enable the creation of embeddings with hundreds or even thousands of dimensions
Why is that cool?
Because we can do math with it!
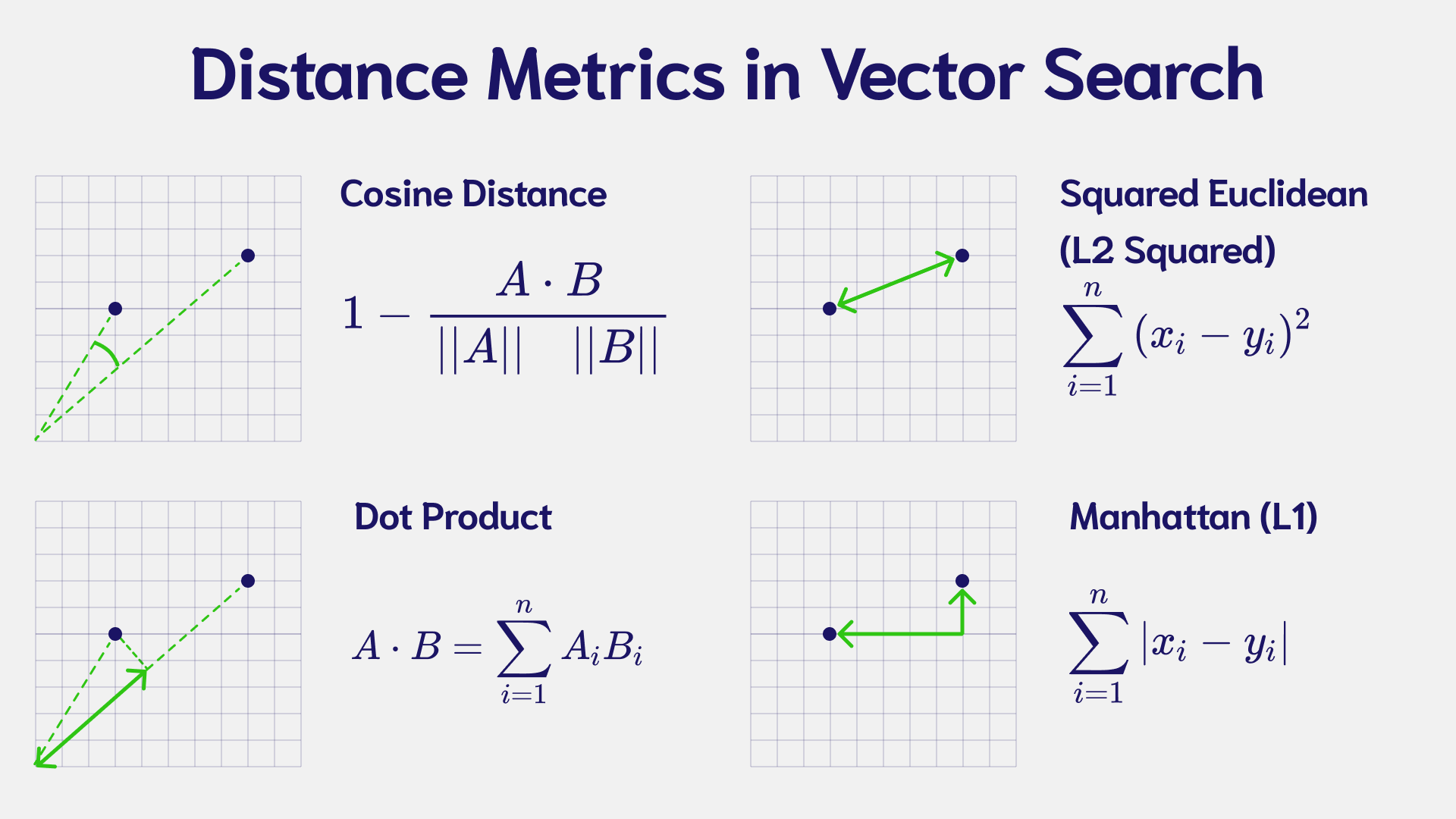
Used in most cases: Cosine Distance
Cosine distance is defined as the distance of the angle between two vectors normalized to unit length, ranging from 0 to 2
- 0 = Synonymous (the same)
- 1 = Orthogonal (no relation)
- 2 = Antonymous (the opposite)
the shortest distance win, we assume everything below 0.1 as a very very close match
In PHP we calculate it like this:
function distance($a,$b):float
{
return 1 - (dotp($a,$b) /
sqrt(dotp($a,$a) * dotp($b,$b))
);
}
// calculating the dot-product
function dotp($a,$b):float
{
$products = array_map(function($da, $db) {
return $da * $db;
}, $a, $b);
return (float)array_sum($products);
}
This will produce a floating point number between 0 and 2
In our examples we use
- OpenAI's embedding models
- Model: text-embedding-ada-002
- (Alternative: text-embedding-3-small)
- Uses 1536 dimensions
- Is normalized to unit length (ranged between -1 and 1)
How does such an embedding look like?
the word "Queen"
[-0.0045574773,-0.0067263762,-0.002498418,
-0.018243857,-0.01689091,0.010516719,-0.0076504247,
-0.024046184,-0.017365139,-0.012818122,0.0145058185,
0.022330591,0.014533714,-0.0029691597,-0.018801773,
0.008884814,0.043322187,0.021061333,0.029513761,
-0.008801127,0.0020712635,0.014136199,-0.005460604,
0.003598559,-0.005296716,-0.010230786,0.0072319875,
... ,-0.011262931]encoded in 1536 dimensions, capturing meaning, context and relations
How do I get an embedding in PHP?
composer req openai-php/client
function getEmbedding(string $text): array
{
$client = OpenAI::client(getenv('OPENAIKEY'));
$result = $client->embeddings()->create([
'model'=>'text-embedding-ada-002',
'input'=>$text,
'encoding_format'=> 'float',
]);
return $result->toArray()['data'][0]['embedding'];
}
Tip: cache the resulting embedding
Monarch + Woman = Queen
That's nerdy and cool, but what can we do with it?
Checking the quality of translations
$embedding = new Embedding();
$text1 = $argv[1];
$text2 = $argv[2];
$d1 = $embedding->calculateEmbedding($text1);
$d2 = $embedding->calculateEmbedding($text2);
$distance = $embedding->distance($d1, $d2);
$rating = $distance > 0.125 ? 'BAD' : 'GOOD';
printf("\n\n%s\n\n%s\n\nDistance: %s\n\nRating: %s\n\n",
$text1, $text2, $distance, $rating);
0.125 is the threshold we defined for us
Normalize unformatted data
$embedding = new Embedding();
$normalizeMe = $argv[1];
$dictionary = $embedding->generateDictionary([
'rock', 'paper', 'scissors', 'lizard', 'spock',
]);
$distances = $embedding->calculateDistances(
$embedding->calculateEmbedding( $normalizeMe ),
$dictionary
); // already sorted
print_r($distances);
printf('the Input "%s" is normalized to "%s"'."\n\n\n",
$normalizeMe,array_keys($distances)[0]);
This way we can normalize random data and text to our domain.
What about BIAS?
$testBias = new Embedding();
$f_p = $testBias->calculateEmbedding( 'female profession');
$m_p = $testBias->calculateEmbedding( 'male profession');
$jobs = [
'Doctor',
'Nurse', // and more professions
];
foreach ($jobs as $job) {
$j_e = $testBias->calculateEmbedding($job);
$d1 = $testBias->distance( $j_e, $f_p );
$d2 = $testBias->distance( $j_e, $m_p );
printf("%s is a profession for %s.\n",
$job, $d1 < $d2 ? 'WOMEN' : 'MEN');
}
Biases are inherent to all AI Models! It always depends on by who and how they are trained!
The RAM
$em = new Embedding();
$theText = $argv[1];
[$keyword, $distance] = $em->getNearestNeighbour(
$em->calculateEmbedding( $theText ),
$em->generateDictionary([
'truck','computer memory','sheep'
])
);
printf("\n\n\n".'"%s" probably is : %s'."\n\n\n",
$theText,$keyword);
Takeway: Models are trained by nerds!
Good thing: you can use embeddings to test the bias in your own models!
Statistical Analysis - Sentiment or emotion
$embedding = new Embedding();
$rateme = $argv[1];
$distances = $embedding->calculateDistances(
$embedding->calculateEmbedding( $rateme ),
$embedding->generateDictionary( [
'joy', 'sadness', 'anger', // ... 120 more emotions
])
);
$filtered = array_filter( $distances, function ( $val ) {
return $val < 0.25;
});
printf('The input "%s" carries the sentiments "%s"',
$rateme, implode( ', ', array_keys( $filtered ) ) );
More fun things you can do with embeddings
checking the "mood" - this how Zoom knows how a conference call went
Input parser for spoken language
finding similar products (closest neighbour) - as an alternate recommendation based on loose couplings like the order history rather than keywords or categories
creating a search by "intention" not keyword
or a chat feature based on your database
How to store embeddings
- Vector Databases
- Qdrant
- Azure Cognitive Search
- Pinecone
- Redis (redis-stack-server)
- Solr 9.10
- ...
- Relational Databases
- PostgreSQL (pgvector extension)
- MySQL 9.0 (VECTOR datatype)
- MariaDB 11.6-vector-preview
- Filesystem Cache
Alternatives to OpenAI
Ollama has 3 embedding models available (Rest API)
Google Vertex-AI has 2 embedding models
Algorithm based models, like Tensorflow, Word2Vec, Bayes etc. pp.
Semantic Search in Redis
Talk: Let's Build an AI-Driven Search on Our Website
- Defining our JSON structure
- Creating an Index in Redis
- Storing Embeddings in the Index
- Searching Data using the Index
Semantic Search in TYPO3
Tim Lochmüllers Extensions:
- EXT:index
- EXT:seal
- WIP: EXT:seal_ai
Michał Cygankiewicz, Krystian Chanek
Special Thanks go to
Barry Stahl - who gave me the insipiration and examples for this talk
production ready coding
What are your questions?

Twitter: @FoppelFB | Mastodon: @foppel@phpc.social
fberger@sudhaus7.de | https://sudhaus7.de/