
Let's Build an AI-Driven Search on Our Website
with embeddings and Redis
TYPO3 Developer Days 2025
Frank Berger
A bit about me
- Frank Berger
- Head of Engineering at sudhaus7.de, a label of the B-Factor GmbH, member of the code711.de network
- Started as an Unix Systemadministrator who also develops in 1996
- Working with PHP since V3
- Does TYPO3 since 2005

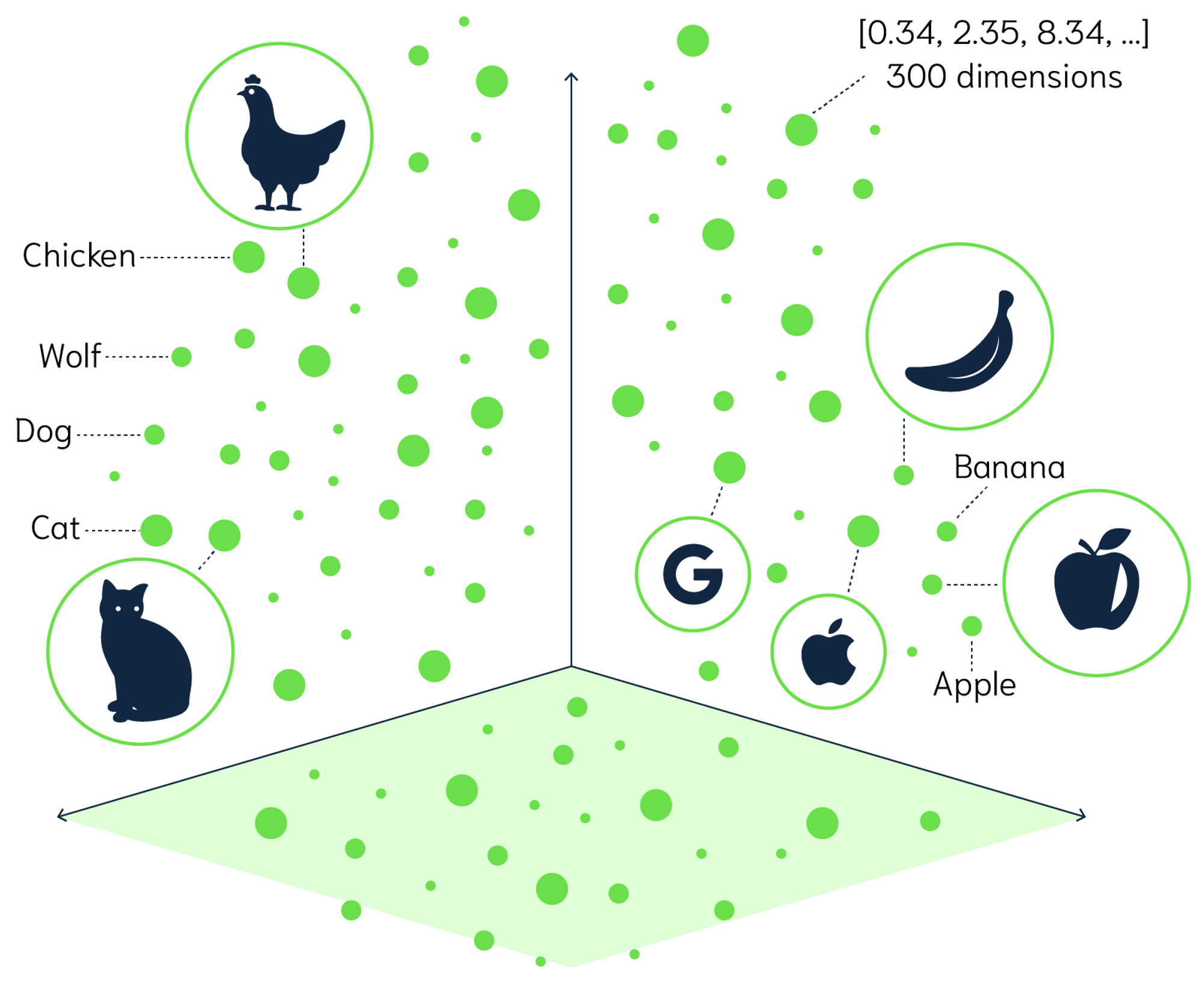
What is an Embedding?
A point in multi-dimensional space, described by a vector
Mathematically represent characteristics and meaning of a word, phrase or text
It encodes both semantic and contextual information
AI and LLMs enable the creation of embeddings with hundreds or even thousands of dimensions
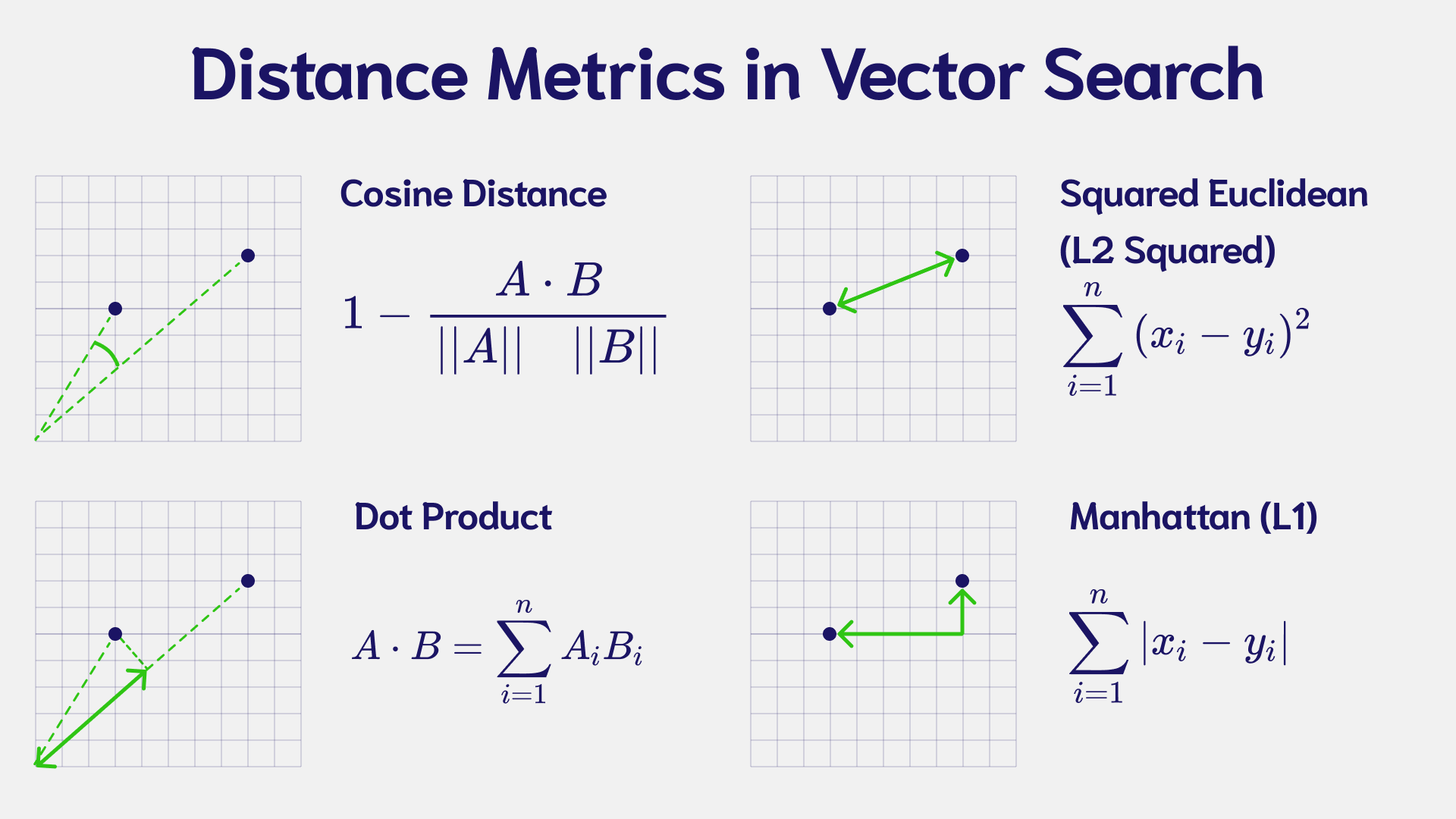
Used in most cases: Cosine Distance
Cosine distance is defined as the distance of the angle between two vectors normalized to unit length, ranging from 0 to 2
- 0 = Synonymous (the same)
- 1 = Orthogonal (no relation)
- 2 = Antonymous (the opposite)
the shortest distance wins
In PHP we can calculate it like this:
function distance($a,$b):float
{
return 1 - (dotp($a,$b) /
sqrt(dotp($a,$a) * dotp($b,$b))
);
}
// calculating the dot-product
function dotp($a,$b):float
{
$products = array_map(function($da, $db) {
return $da * $db;
}, $a, $b);
return (float)array_sum($products);
}
This will produce a floating point number between 0 and 2
What does such an embedding look like?
the word/concept "Queen"
[-0.0045574773,-0.0067263762,-0.002498418,
-0.018243857,-0.01689091,0.010516719,-0.0076504247,
-0.024046184,-0.017365139,-0.012818122,0.0145058185,
0.022330591,0.014533714,-0.0029691597,-0.018801773,
0.008884814,0.043322187,0.021061333,0.029513761,
-0.008801127,0.0020712635,0.014136199,-0.005460604,
0.003598559,-0.005296716,-0.010230786,0.0072319875,
... ,-0.011262931]encoded in 768 dimensions, capturing meaning, context and relations
How do I get an embedding in PHP?
composer req openai-php/client
ollama run nomic-embed-text:latest
$client = OpenAI::factory()
->withBaseUri('http://localhost:11434/v1')
->make();
$result = $client->embeddings()->create([
'model'=>'nomic-embed-text',
'dimensions'=>768,
'input'=>$text,
'encoding_format'=> 'float',
]);
return $result->toArray()['data'][0]['embedding'];
Other good embeding engine: snowflake-arctic-embed2
Monarch + Woman = Queen
This is how LLMs calculate what you 'mean'
Normalize unformatted data
$embedding = new Embedding();
$normalizeMe = $argv[1];
$dictionary = $embedding->generateDictionary([
'rock', 'paper', 'scissors', 'lizard', 'spock',
]);
$distances = $embedding->calculateDistances(
$embedding->calculateEmbedding( $normalizeMe ),
$dictionary
); // already sorted
print_r($distances);
printf('the Input "%s" is normalized to "%s"'."\n\n\n",
$normalizeMe,array_keys($distances)[0]);
This way we can normalize random data and text to our domain.
Embeddings in Redis
docker run --name my-Redis-container \
-p 6378:6379 -v `pwd`/dockerRedisdata:/data \
-d Redis/Redis-stack-server:latest- Defining our JSON structure
- Creating an Index in Redis
- Storing Embeddings in the Index
- Searching Data using the Index
"Index" is here a synonym for a table and an index in an SQL database
Defining our JSON structure
{
uid: 123,
pid: 111,
table: 'tt_content',
text: 'lorem ipsum vitae dolor sit amit...',
slug: 'https://my.domain.de/the/path/to/the/page',
embedding: [0.45633,-0.567476,0.126775,...]
}
Creating an Index in Redis
FT.CREATE idx:MYINDEX ON JSON PREFIX 1 text: SCORE 1.0
SCHEMA
$.uid NUMERIC
$.pid NUMERIC
$.table TEXT WEIGHT 1.0 NOSTEM
$.text TEXT WEIGHT 1.0 NOSTEM
$.slug TEXT WEIGHT 1.0 NOSTEM
$.embedding AS vector VECTOR FLAT 6 TYPE FLOAT32 DIM 1536 DISTANCE_METRIC COSINE
Creating an Index in Redis
in PHP Using pRedis/pRedis
$client = new Predis\Client([ 'port'=>6378 ]);
$fields = [
new NumericField('$.uid', "uid"),
new NumericField('$.pid', "pid"),
new TextField('$.table', "table"),
new TextField('$.text', "text"),
new TextField('$.slug', "slug"),
new VectorField( '$.embedding', 'FLAT' ,[
'TYPE','FLOAT32',
'DIM','1536',
'DISTANCE_METRIC','COSINE'
],'vector')
];
$arguments = new CreateArguments();
$arguments->on('JSON' )->prefix( ['MYINDEX:'])->score(1.0);
$status = $client->ftcreate(
'idx:MYINDEX', $fields, $arguments
);
var_dump($status);Storing Embeddings in the Index
// $row is from the TYPO3 database,
// or the TYPO3 Datahandler or similar
// $table for example tt_content
$text = sprintf("%s\n%s",
$row['header'],
strip_tags( $row['bodytext'] )
);
$key = 'MYINDEX:'.$table.':'.$row['uid'];
$set = [
'uid'=>$row['uid'],
'pid'=>$row['pid'],
'slug'=>$base.$row['slug'],
'table'=>$table,
'text' => $text,
'embedding'=>getEmbedding($text)
];
$client = new Predis\Client(['port'=>6378]);
$client->jsonset( $key, '$', json_encode($set) );
Searching Data using the Index
use Predis\Command\Argument\Search\SearchArguments;
$searchEmbedding = getEmbedding( $searchTerm );
$client = new Predis\Client([ 'port' => 6378 ]);
$searchArguments = new SearchArguments();
$searchArguments
->dialect( 2 ) // must be 2 for vector
->sortBy('__vector_score') // closest neighbour by definition
->addReturn( 6, '__vector_score', 'uid','pid'
,'text','table','slug')
->limit(0, 10)
->params( [
'query_vector',
pack( 'f1536', ... $searchEmbedding )
]);
$rawResult = $client->ftsearch(
'idx:MYINDEX',
'(*)=>[KNN 100 @vector $query_vector]',
$searchArguments
);
[$count,$results] = normalizeRedisResult( $rawResult );
Searching Data using the Index
normalizing the Redis-result
The RAW Result:
Array (
[0] => 3 // amount of result sets
[1] => MYINDEX:tt_content:2467 // KEY first set
[2] => Array (
[0] => __vector_score
[1] => 0.18477755785
[2] => uid
[3] => 2467
[4] => text
[5] => Contact
[6] => table
[7] => tt_content
[8] => pid
[9] => 265
[10] => slug
[11] => https://www.tcworld.info/contact
)
[3,4] // next key and set
[5,6] // next key and set
)
Searching Data using the Index
normalizing the Redis-result
function normalizeRedisResult(array $result):array {
$count = array_shift($result);
$return = [];
foreach($result as $value) {
if(!is_array($value)) $key=$value;
else {
$set = [];
for($i=0,$l=count($value); $i<$l; $i=$i+2) {
$k = $value[$i];
$set[$k] = $value[$i+1];
}
$return[ $key ] = $set;
}
}
return [$count,$return];
}
Searching Data using the Index
normalizing the Redis-result
Array
(
[MYINDEX:tt_content:2509] => Array
(
[__vector_score] => 0.194359481335
[uid] => 2509
[text] => lorem ipsum vitae...
[table] => tt_content
[pid] => 273
[slug] => https://www.tcworld.info/faq
)
[MYINDEX:tt_content:2528] => Array ()
[MYINDEX:tt_content:2567] => Array ()
)
want to see this stuff in action?
CSS: https://picocss.com/
Javascript: VanillaJS
Embeddings: OpenAI text-embedding-3-small
Usecases
- Product Search by similarity
- Better Searches for API provided data (Redmine for example)
- Faster quicksearches
- Categorization/Normalisation of unstructured content
Caveats
- You have to stick to a model and dimension
- You might need to re-index sometimes
Alternatives to Redis
- Qdrant
- Pinecone (TYPO3 extension available)
- Weaviate
- PostgresSQL Vector
- ... many more
Next steps
- More Abstraction
- DataHandler Support
- Search Plugin (?)
Shameless plug
smartbrew.ai
What are your questions?

Thank you, I am here all weekend
Twitter: @FoppelFB | Mastodon: @foppel@phpc.social
fberger@sudhaus7.de | https://sudhaus7.de/